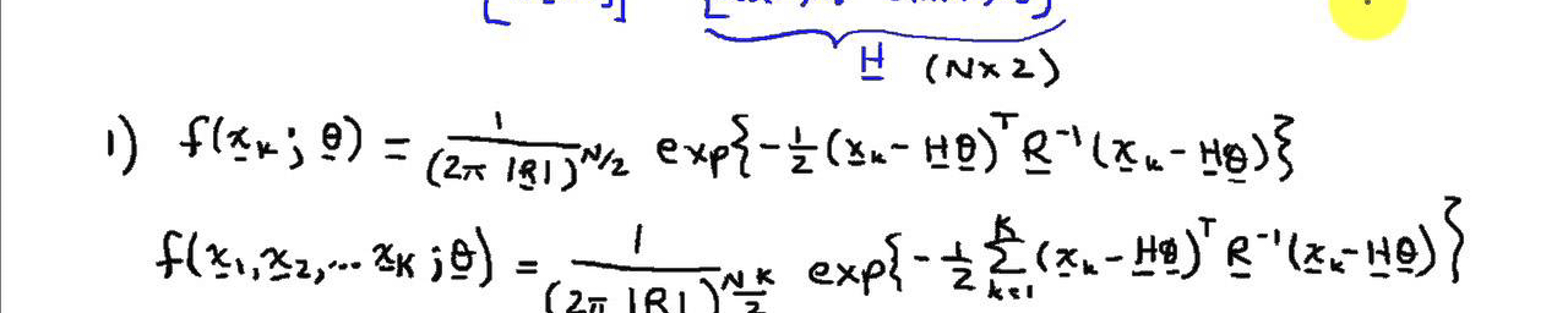

Fisher InformWHAT?
Hi you! Here I’m going to talk to you a little bit about Fisher Information. If you’re reading this post, I’m sure you’ve heard of it, and can now appreciate the beautiful classic theory of mathematical statistics about the likelihood function. But let’s not lose focus, and let’s talk about Fisher Information.
For begin with, do you know what formula is down here?
\[\mathbb{E}\left[ \left( \frac{\partial \log f(X|\theta)}{\partial \theta} \right)^2 \right]\]Maybe that way you don’t recognize it, but maybe that makes more sense.
\[-\mathbb{E}\left[ \frac{\partial^2 \log f(X|\theta)}{\partial \theta^2} \right]\]If you said Fisher Information, you were right. And if you don’t know that, I would like to tell you that this quantity is the infamous Fisher Information, and that’s what I’m going to talk about here. And I will try my best not to show more formulas, because I know it scares people (even though I love it).
The Fisher Information is an important quantity in Mathematical Statistics, which plays a fundamental role in classical statistics, especially in the asymptotic theory of Maximum-Likelihood Estimation (MLE), and in the Cramér-Rao lower bound (I will make a post just about that).
Informally, Fisher Information provides a measure of the amount of “information” that a random variable carries over a parameter \(\theta\). More formally, the Fisher Information is the variance of the score function (I will also post about it).
In this post I commented on the likelihood function and why we maximize it to obtain an estimate of unknown parameters, also known as MLE. Now let’s go back to that post. The log-likelihood is a function of \(\theta\), and is random because it depends on \(\mathbf{X}\), and we would like to find an unique maximum by locating the value of \(\theta\) that maximizes the log-likelihood function.
We usually find \(\theta\) by equating the first derivative of the log-likelihood function to zero and solving the equation. And to know how accurate the MLE is, we need to look at the curvature of the log-likelihood function around its maximum point, because if this function has a strong and accentuated curvature it would have a high negative expected second derivative and therefore a larger Fisher Information, which indicates more information through \(\mathbf{X}\) about \(\theta\).
I hope you understand a little more about Fisher Information and how we should interpret it, as it plays a key role in statistics and appears in many asymptotic analysis (due to what is known as the Laplace approximation). Finally, remember that this quantity is directly linked to the amount of information that the sample brings about the parameter, which will directly reflect on the variance of the estimate.
I see ya in the next post, or on twitter.
References
Bolfarine, Heleno, and Mônica Carneiro Sandoval. Introdução à inferência estatística. Vol. 2. SBM, 2001.
Casella, George, and Roger L. Berger. Statistical inference. Vol. 2. Pacific Grove, CA: Duxbury, 2002.
DUDEWICZ, Edward J.; MISHRA, Satya. Modern mathematical statistics. John Wiley & Sons, Inc., 1988.
Ly A, Marsman M, Verhagen J, Grasman RP, Wagenmakers EJ. A tutorial on Fisher information. Journal of Mathematical Psychology. 2017.
Leave a comment